
티스토리 뷰
많은 일반적인 알고리즘은 하나의 프로세서에서 작동함을 가정하지만, 현실의 계산에서는 컴퓨팅 기계가 하나의 프로세서가 아닌 여러 프로세서를 사용할 수도 있다. Parallel Algorithm의 경우는 효율성을 위해서 여러 개의 프로세서를 두고 동시에 중앙적으로 컨트롤하지만, 가끔은 여러 프로세서를 두는 것이 단순 효율성 때문이 아니라 실제적인 시공간적 제약에 의해서일 수도 있다. 예를 들어, 세계 각지에서 정보를 모으는 컴퓨터가 있고, 이 정보들을 한데 모아서 특정한 계산을 하고 싶은데, 정보들이 하나로 모으기에는 너무 크거나, 아니면 장거리 네트워크를 사용하는 것이 아주 비효율적인 상황들이 있을 것이다.
Distributed Algorithm이란 어떠한 알고리즘이 하나의 프로세서가 아니라 여러 분할된 프로세서에서 작동됨을 가정하는 알고리즘을 뜻한다. 이 때 각 프로세서가 가지고 있는 정보들은 Global하지 않고, 해당 프로세서 근처에 있는 정보들만 알 수 있는 경우가 많다. Distributed Algorithm의 각각의 프로세서 성능은 충분히 좋음을 가정하지만, 인접한 프로세서가 정보를 교환하는 수를 최소화해야 한다. 이 때 정보 교환의 수가 일반적인 알고리즘보다 월등히 낮으면, 이 때는 효율적인 Distributed Algorithm이 존재한다고 할 수 있다.
Distributed Algorithm은 예전에 Distributed Code Jam이라는 프로그래밍 대회로도 다뤄진 적이 있었다. 당시에 나도 재미있게 참가했고 주위 반응도 좋았는데, 기술적인 문제로 오래 가지 못했고 현재는 Code Jam 자체가 사라져 버렸다. 어쨌든 여기 있는 문제들은 PS를 했다면 재미있게 읽어볼만한 내용도 많고, 실제 PS 문제와 관련있는 경우도 있어서 (Chapter 1), 실제 연구에서 다루는 알고리즘들이 어떠한 것인지를 익혀보고 싶다면 한번 읽어 보는 것을 추천한다.
1. Coloring Rooted Trees
Distributed Graph Algorithm에 대해서 논하기 위해서는 어떠한 모델을 가정하는지에 대한 언급이 필수적이다. 이 글에서 사용할 모델은 다음과 같이 정의된다. 다른 모델을 쓰는 알고리즘도 많음에 유의하라.
Definition (LOCAL model). 무향 무가중치 단순 그래프 $G = (V, E)$ 가 주어지고 $V = {1, 2, \ldots, n}$ 이다. 각 노드 $v \in V$ 에 대해 독립적인 프로세스가 있다. 이 프로세스는 그래프에 대한 정보를 알지 못하고, 다만 자신의 번호와 그래프의 정점 수를 알고 있다. 매 라운드마다, 각 노드는 자신이 아는 정보에 의거해 어떠한 연산을 하고, 연산 후 모든 인접한 정점에 메시지를 보내고, 이후 모든 인접한 정점에서 메시지를 받는다.
Observation. $D$ 를 그래프의 지름이라고 하면, 모든 문제는 $O(D)$ 라운드에 해결 가능하다. (그래프 전체를 얻을 수 있기 때문이다.)
Observation. LOCAL model에서 어떠한 path graph의 2-coloring을 찾는 것은 $\Omega(n)$ 번의 라운드가 필요하다.
Proof. path의 2-coloring은 정확히 두 개 존재한다. $o(n)$ 번의 라운드를 거친다면, 그래프에 있는 $n - o(n)$ 개의 노드들은 자기 양 옆에 있는 $o(n)$ 개의 노드들의 인덱스만 알 수 있으며, 구체적으로 그래프의 양 끝점에 대해서 알 수가 없다. 이것만을 사용한 2-coloring scheme이 존재한다고 하면 - 예를 들어, $o(n)$ 개의 인덱스에서 ${1, 2}$ 로 가고, 임의의 인접한 $o(n)$ 길이의 path에서 다른 결과가 나오는 함수가 존재한다면, 홀수 사이클도 동일한 방식으로 2-coloring할 수 있다.
이 단락에서는 다음 사실을 증명한다. $\log^*(n)$ 을, 어떤 양수에 $n \leftarrow \log(n)$ 을 반복해서 $n \leq 1$ 로 만들고 싶을 때 필요한 최소 반복 횟수라고 정의하자. 다음 사실이 성립한다:
Theorem 1. Rooted tree를 $\log^* n + O(1)$ 번의 라운드에 3-coloring 할 수 있다.
Theorem 2. Rooted tree를 3-coloring하는 것은 $\frac{1}{2} \log^* n - 2$ 번의 라운드가 필요하다.
Proof of Theorem 1.
현재 채색의 최댓값이 $x$ 라 하자 (초기 $n$). $x \leq \binom{2k}{k}$ 인 최소 $k$ 를 잡은 후 $x$ 를 1이 $k$ 개 있는 길이 $2k$ 의 이진 문자열에 대응시킨다. 이제 매 라운드마다 다음 과정을 거치면, 최댓값이 $2k$ 인 채색으로 현재 채색을 압축할 수 있다:
- $x$ 가 루트가 아니라면, 부모 $p(x)$ 의 채색이 주어질 때, 내 색을 $p(x)$ 에 속하지 않고 $x$ 에 속하는 최소 비트 인덱스로 정의한다.
- $x$ 가 루트라면 $p(x)$ 를 길이 $2k$ 의 0 문자열로 두고 동일하게 한다.
이를 $x > 4$ 일때까지 반복한다.
$x = 4$ 일 경우에는 두 번의 라운드로 색의 개수를 줄일 수 있다.
- 첫번째 라운드에는, 각 노드의 채색을 자기 부모의 채색으로 바꾼다. 루트 노드에 대해서는, 원래 색과 다른 아무 색이나 고른다.
- 첫번째 라운드가 끝나도 여전히 Valid coloring이며, 또한 노드의 모든 자식이 같은 색을 가진다.
- 두번째 라운드에서, 만약 현재 색이 $4$ 라면, 부모와 자식의 색이 아닌 다른 색으로 바꾼다. 노드의 모든 자식이 같은 색을 가지니, 못 쓰는 색은 2가지 (부모, 자식) 이고, 남는 색이 존재한다.
Remark 1.1. Rooted tree가 아니라 Pseudoforest (각 노드의 outdegree가 최대 1) 이어도 동일하게 하면 된다.
Remark 1.2. 이 알고리즘을 사용하여, 최대 차수가 $\Delta$ 인 임의의 그래프를 $\Delta + 1$-coloring할 수도 있다. 각 노드에 대해서, $\Delta$ 크기의 배열을 선언하고, 배열의 각 원소에 서로 다른 인접한 노드를 대응시키자. 이후 배열의 각 원소에 대해서 인접한 노드를 부모로 두고 (없으면 루트처럼 하고) 위 알고리즘을 사용하여 배열의 원소를 $[1, 4]$ 범위로 줄이자. 이렇게 한 후 각 배열의 원소를 $4^\Delta$ 크기의 정수로 두면, 올바른 Coloring을 얻을 수 있다 (이해가 잘 안되면, 알고리즘이 implicit하게 그래프를 $\Delta$ 개의 pseudoforest로 분해했다고 생각하면 쉽다). 여기에 $C+1$-coloring을 $C$-coloring으로 변환하는 것을 Theorem 1의 마지막 단계처럼 반복하면, $\Delta+1$ 까지 줄일 수 있다. 지금은 $\Delta$ 가 상수라고 두고 다소 Naive하게 접근했지만, 이후 이보다 더 효율적인 알고리즘을 뒤에서 다룰 것이다.
Remark 1.3. 2023 선발고사의 야유회 문제는 이 Theorem을 바탕으로 출제하였다.
Proof of Theorem 2.
Directed path를 $t < \frac{1}{2} \log^* n - 2$ 번의 라운드 안에 3-coloring하는 결정론적 알고리즘이 존재한다고 하자. 알고리즘은 최대 $2t + 1$ 개의 노드의 색을 알 수 있기 때문에, 어떠한 결정론적 알고리즘은 $2t + 1$ 개의 정점 번호 수열이 주어졌을 때 이를 ${1, 2, 3}$ 에 매핑하는 함수라고 생각할 수 있고, 우리는 이러한 함수가 존재하지 않음을 보여야 한다.
Definition. 다음과 같은 성질을 만족하는 함수 $B$ 를 $(k, q)$-coloring 이라고 하자. 임의의 증가하는 정수열 $1 \le a_1 < a_2 < \ldots < a_k < a_{k + 1} \le n$ 에 대해:
- $B(a_1, a_2, \ldots, a_k) \in [q]$
- $B(a_1, a_2, \ldots, a_k) \neq B(a_2, a_3, \ldots, a_{k+1})$
$a$ 의 증가 조건에 의구심을 가질 수 있는데, directed path가 monotonically increasing하다는 가정을 추가로 넣은 것이다. 인덱스가 monotonically increasing한 경우에 알고리즘을 찾을 수 없다면, 임의의 경우에서도 찾을 수 없을 것이니, 더 강한 조건이라 상관이 없다.
이제 Theorem 2를 증명하기 위해 몇 가지 Lemma를 정의한다.
Lemma 2.1. $q < n$ 일 때 $(1, q)$-coloring은 존재하지 않는다. (비둘기집의 원리를 생각해 보면 자명)
Lemma 2.2. $(k, q)$-coloring이 존재한다면, $(k - 1, 2^q)$-coloring도 존재한다.
Proof. 임의의 증가하는 정수열 $1 \le a_1 < a_2< \ldots < a_{k-1} \le n$ 에 대해, $B^\prime(a_1, a_2, \ldots, a_{k-1})$ 을 $B(a_1, a_2, \ldots, a_{k-1}, a_k) = i$ 인 $a_k > a_{k-1}$ 가 존재하는 $i$ 의 집합으로 정의하자. 즉, $B^\prime$ 은 $[q]$ 의 부분집합이고, 이는 $B^\prime$ 을 $[1, 2^q]$ 범위의 정수로 대응시킬 수 있다는 것이다. 이제 $B^\prime(a_1, a_2, \ldots, a_{k-1}) \neq B^\prime(a_2, a_3, \ldots, a_{k})$ 임을 증명하면, $B^\prime$ 이 $(k-1, 2^q)$-coloring임을 증명할 수 있다.
$B^\prime(a_1, a_2, \ldots, a_{k-1}) = B^\prime(a_2, a_3, \ldots, a_k)$ 를 만족하는 증가하는 정수열 $1 \le a_1 < a_2< \ldots < a_k \le n$ 이 존재한다고 가정하자. 이 때 $B(a_1, a_2, \ldots, a_k)$ 의 값은 무엇일까? 이 값은 일단 정의에 의해 $B^\prime(a_1, a_2, \ldots, a_{k-1})$ 에 속해야 한다. 한편, 이 값이 $B^\prime(a_2, a_3, \ldots, a_{k})$ 에 속하게 된다면, $B(a_1, a_2, \ldots, a_k)$ 와 값이 같은 $B(a_2, a_3, \ldots, a_{k+1})$ 가 존재하게 되니 그래서는 안된다. 종합하면, $B(a_1, a_2, \ldots, a_k)$ 는 정의되지 않으며 이는 가정에 모순이다. $\blacksquare$
두 Lemma가 있으면 이제 Theorem 2의 증명이 가능하다. $(\log^*n - 4, 3)$-coloring 이 존재한다고 하자. Lemma 2.2 의 내용을 반복하면, $(\log^* n - 5, 2^3)$-coloring, $(\log^* n - 6, 2^8)$-coloring, $(\log^* n - 7, 2^{2^8})$-coloring ... 결국 $q < n$ 에 대한 $(1, q)$-coloring 이 존재한다는 결론에 도달하게 되며, 이는 Lemma 2.1에 모순이다. $\blacksquare$
2. Coloring Unrooted Trees
위 알고리즘의 Rooted tree, 즉 모든 정점에 대해 어떠한 부모 가 존재한다는 가정은 생각보다 강력하다. 부모를 알지 못 할 경우 $\log^* n$ 수준으로 효율적인 알고리즘은 얻을 수 없다. 하지만, 그래도 $\log n$ 정도의 라운드를 보장하는 알고리즘은 존재한다.
Theorem 3. $O(\log n)$ 번의 라운드를 진행하면 임의의 $n$ 개의 노드의 트리에 대해 $3$-coloring을 얻을 수 있다.
Theorem 4. (결정론적 알고리즘을 사용하여) 최대 차수가 $\Delta$ 이며 크기 $n$ 인 트리를 $o(\Delta / \log \Delta)$ 개 미만의 색으로 칠하기 위해서는 최소 $\Omega(\log_{\Delta} n)$ 회의 라운드가 필요하다.
Corollary. 크기 $n$ 이며 최대 차수가 상수개인 트리를 $3$ 색으로 칠하기 위해서는 최소 $\Omega(\log n)$ 회의 라운드가 필요하다.
먼저 Theorem 4부터 증명한다. Theorem 4를 증명하기 위해서는 다음 Lemma가 필요한데, 여기서는 증명하지 않는다.
Lemma 4.1. 충분히 큰 $n$ 에 대해서 모든 노드의 차수가 $\Delta$ 이고, 최소 길이 사이클 (girth) 의 길이가 $\Omega(\log_{\Delta} n)$ 이며 최소 채색 수 (chromatic number) 가 $\Omega(\Delta / \log \Delta)$ 인 그래프가 존재한다.
Proof of Theorem 4. 귀류법을 사용한다. 최대 차수가 $\Delta$ 이며 크기 $n$ 인 트리를 $o(\log_{\Delta} n)$ 라운드에 $o(\Delta / \log \Delta)$ 개 미만의 색으로 칠하는 알고리즘이 있다고 하자. 이 알고리즘을 Lemma 4.1에서 주어진 그래프 에 적용시켰을 때, 알고리즘의 각 노드는 알고리즘이 종료할 때까지 그래프가 트리인지 아닌지를 분간할 수 없다 - $o(\log_{\Delta} n)$ 거리의 정점의 정보만 얻기 때문에, 각 노드가 얻은 그래프의 부분적 정보에는 사이클이 없기 때문이다.
알고리즘은, 자신이 처리한 그래프가 트리라고 생각하고 색칠을 진행할 것이다 (구체적으로, deterministic algorithm이니, 자신이 가진 정보가 트리인 이상 대응되는 color가 존재해야만 한다). 그래프는 $o(\Delta / \log \Delta)$ 개의 색으로 색칠할 수 없고, 알고리즘은 잘 종료하니, 결국 채색이 틀렸다는 결론에 도달하게 된다. 다시 말해, 인접한 두 노드가 같은 색으로 칠해진다.
같은 색으로 칠해진 두 노드를 기준으로, $o(\log_{\Delta} n)$ 거리에 있는 정점들을 모아 induced subgraph를 만들자. 이 induced subgraph는 트리이고, deterministic algorithm은 이 트리의 채색을 앞과 똑같이 실패할 것이다. 고로 가정에 모순이다. $\blacksquare$
이제 Theorem 3을 알고리즘을 통해 증명한다.
Proof of Theorem 3.
Step 1. $T = (V, E)$ 를 다음과 같은 과정으로 분해한다: 먼저, $L_1$ 을 $T$ 에서 차수가 2 이하인 정점들의 집합으로 두자. 이후 $T$ 에서 $L_1$ 에 속하는 정점을 지우고 (포레스트가 된다), $L_2$ 를 남은 정점들 중 차수가 2 이하인 정점들의 집합... 과 같이 반복한다. 임의의 트리에 대해서, 차수가 3 이상인 정점의 비율이 $r$ 이라 하자. 이 때 $3rn + 1(1-r)n \leq 2n - 2 \leq 2n$ 이 성립하고, 고로 $r \leq 1/2$ 라 이 과정은 $\log n$ 번 이후 종료된다.
Step 2. 각 Induced subgraph $T[L_i]$ 를 3개의 색으로 색칠한다. $T[L_i]$ 는 최대 차수가 2 이하이니, Theorem 1 (사실 Theorem 1으로는 충분하지 않고, Remark 1.2 에 서술된 버전) 을 적용하여 색칠할 수 있다.
Step 3. $T[L_i]$ 에 대한 개별적인 Coloring을 하나로 합쳐야 한다. $T[L_{i+1} \cup \ldots \cup L_k]$ 에 대한 올바른 3-coloring이 주어졌다고 하자. 먼저, $T[L_i]$ 에 있는 정점 중 1번 색을 가진 노드들에 대해서, 남는 색을 아무거나 배정한다. 그 다음, 2번 색에 대해서, 3번 색에 대해서 순서대로 동일하게 해 준다 (3번의 라운드 사용). 각 색을 가진 노드들은 독립 집합을 이루고, $T[L_i]$ 의 차수는 2 이하이기 때문에, 이 방식으로 $T[L_i \cup \ldots \cup L_k]$ 에 대한 올바른 3-coloring을 찾을 수 있다.
3. Coloring General Graphs
일반적인 그래프에 대한 최소 채색을 구하는 것은 NP-hard이지만, 그래프의 최대 차수가 $\Delta$ 일 경우 $(\Delta + 1)$ coloring을 선형 시간에 구하는 것은 어렵지 않다. 그래프의 정점들을 아무 순서대로 보면서, 남은 색을 배정하는 것을 반복하면 되기 때문이다. 이 단락에서는 LOCAL model에서 $(\Delta + 1)$-coloring을 $O(\Delta + \log^* n)$ 에 구하는 알고리즘을 소개한다. 알고리즘 자체는 대단히 효율적이지만 그 내용은 꽤 복잡하기 때문에, 단계적으로 천천히 살펴보자.
3-1. Linial's Coloring Algorithm
Theorem 5. 정점이 $n$ 개이고 최대 차수가 $\Delta$ 인 그래프를 $O(\log^* n)$ 시간에 $O(\Delta^2)$ 개의 색으로 칠하는 Deterministic Algorithm이 존재한다.
Theorem 5의 알고리즘은 앞에서와 유사하게 $k$-coloring이 주어졌을 때 색의 범위를 줄여서 $k^\prime$-coloring으로 반복적으로 압축하는 방식이다. 구체적으로, 다음과 같은 Lemma를 보일 수 있다:
Lemma 5.1. 최대 차수가 $\Delta$ 인 그래프의 $k$-coloring이 주어졌을 때, 우리는 $k^\prime$-coloring 을 구할 수 있다. 이 때 $k^\prime = O(\Delta^2 \log k)$ 을 만족한다. 만약 $k \leq \Delta^3$ 일 경우 추가적으로 $k^\prime = O(\Delta^2)$ 를 만족한다.
Lemma 5.1 이 참이라면 Theorem 5는 자연스럽게 따라오니, Lemma 5.1을 증명하자.
Definition: Cover free families. $\Delta, k, k^\prime$ 에 대해, 집합들 $S_1, S_2, \ldots, S_k \subseteq [k^\prime]$이 $\Delta$-cover free family라는 것은, 임의의 $\Delta+1$ 개의 서로 다른 인덱스 $i_0, i_1, \ldots, i_\Delta \in [k]$ 에 대해 $S_{i_0} \setminus (\cup_{j = 1}^{\Delta} S_{i_j}) \neq \emptyset$ 임을 뜻한다. 다시 말해, $S$ 에서 임의의 $\Delta$ 개의 집합을 잡아서 합집합을 취해도, 이것이 다른 어떠한 집합의 superset이 되는 일이 없다는 뜻이다.
$\Delta = 1$ 인 경우로 생각해 보면 어떨까? $k^\prime$ 이 고정되었을 때, 어떠한 집합이 다른 집합의 부분집합이 되지 않는다는 조건 하에, 최대 몇 개의 집합을 만들 수 있을까? 사실, 크기 $k^\prime / 2$ 의 모든 부분집합이 그러한 집합의 대표적인 사례이고, $\binom{k^\prime}{k^\prime / 2}$ 가 만들 수 있는 집합의 최대 개수이다 (이를 Sperner Theorem이라 한다). 즉, Theorem 1에서 사용한 Construction은 $\Delta = 1$ 에 대한 Optimal construction 이고, Cover free families는 그러한 개념의 일반화로 볼 수 있다.
Lemma 5.1의 증명 방향도 Theorem 1과 유사하게 구성하여, 충분히 큰 Cover free family가 존재하고, 이 Cover free family를 사용하면 숫자를 압축할 수 있다는 식으로 진행한다. 아래 Lemma는 Cover free family의 존재성을 보이며, 일단 바로 증명하지는 않는다.
Lemma 5.1.1. 임의의 $k, \Delta$ 에 대해, $k^\prime = O(\Delta^2 \log k)$ 가 존재하여 $S_1, S_2, \ldots, S_k \subseteq [k^\prime]$이 $\Delta$-cover free family 을 이룬다.
Lemma 5.1.2. 임의의 $k, \Delta \geq k^{1/3}$ 에 대해, $k^\prime = O(\Delta^2)$ 가 존재하여 $S_1, S_2, \ldots, S_k \subseteq [k^\prime]$이 $\Delta$-cover free family 을 이룬다.
이러한 Cover free family가 존재할 때 Lemma 5.1을 증명하는 건 Theorem 1의 증명과 동일하다:
Proof of Lemma 5.1. 현재 $1, 2, \ldots, k$ 범위의 숫자로 구성된 coloring이 주어질 때, 이 숫자를 Cover free family의 집합 $S_1, S_2, \ldots, S_k$ 에 대응시킨다. 정의에 의해 각 노드 $v$ 에 대해서 $S_v$ 에 속하면서 $\cup_{w \in adj(v)} S_w$ 에 속하지 않는 수가 존재하며, 이 수는 $[k^\prime]$ 에 속한다. 새로운 color를 이 수로 정하면, 인접한 두 노드가 같은 색을 가질 수 없다. $\blacksquare$
이제 남은 것은 Cover free family의 존재를 보이는 것이다.
Proof of Lemma 5.1.1. Probabilistic method를 사용한다. 충분히 큰 상수 $C \geq 2$ 에 대해 $k^\prime = C \Delta^2 \log k$ 라고 하자. 각 $S_i$ 는, 단순히 $[k^\prime]$ 의 각 원소를 $\frac{1}{\Delta}$ 확률로 넣어서 구성한다. 이제 이 random construction이 $1$ 에 가까운 확률로 $\Delta$-cover free family 임을 증명한다. 고로, Cover free family가 존재할 뿐만 아니라 이를 구성할 수 있는 효율적인 알고리즘도 존재한다.
임의의 서로 다른 인덱스 $i_0, i_1, \ldots, i_\Delta \in [k]$ 에 대해 $S_{i_0} \setminus (\cup_{j = 1}^{\Delta} S_{i_j}) \neq \emptyset$ 일 확률을 계산해 보자. $q \in [k^\prime]$ 에 대해, $q \in S_{i_0} \setminus (\cup_{j = 1}^{\Delta} S_{i_j})$ 일 확률은 $\frac{1}{\Delta}(1 - \frac{1}{\Delta})^{\Delta} \geq \frac{1}{4\Delta}$ 이고, 고로 저러한 $q$ 가 존재하지 않을 확률은 최대 $(1 - \frac{1}{4\Delta})^{k^\prime} \leq \exp(-k^\prime / 4\Delta) = \exp(-C\Delta \log k / 4)$ 가 된다. Union bound에 의해, 모든 인덱스 선택에 대해서 저러한 $q$ 가 하나라도 존재하지 않을 확률은
$k (k - 1)^{\Delta} \exp(-C \Delta \log k / 4) \leq \exp(\log k + \Delta \log (k - 1) - C \Delta \log k / 4) \leq \exp(-C\Delta \log k / 8)$
이 된다. 고로 충분히 큰 $C$ 에 대해서 Cover free family는 존재하며, 그 확률도 $1$ 에 가깝다. $\blacksquare$
(사실 Deterministic한 방법은 아니라 Theorem 5의 명제와 충돌한다. 아마 Derandomization이 가능할 것 같긴 하다.)
Proof of Lemma 5.1.2. Algebraic proof를 시도한다. $q$ 를 $[3\Delta, 6\Delta]$ 구간에 있는 소수로 두자 (베르트랑 공준에 의해 항상 존재한다). $\mathbb{F}_q$ 를 prime field of order $q$ 라고 할 때, $\mathbb{F}_q$ 상의 모든 2차 다항식을 $g_i: \mathbb{F}_q \rightarrow \mathbb{F}_q$ 로 나타내고, $S_i = {(a, g_i(a)) | a \in \mathbb{F}_q}$ 라고 하자. 이차 다항식의 개수는 $q^3 \geq \Delta^3 \geq k$ 이고, $S_i$ 의 값의 범위는 $k^\prime = q^2 = O(\Delta^2)$ 이다. 고로 $\Delta$-cover free family의 크기 조건은 모두 만족하고, 이것이 superset 조건을 만족하는지만 보면 된다.
다음 두 조건을 관찰하자:
- 모든 $i$ 에 대해 $|S_i| = q$ (자명)
- 모든 $i \neq i^\prime$ 에 대해 $|S_i \cap S_{i^\prime}| \leq 2$ ($g_i - g_{i^\prime}$ 은 0이 아닌 $2$ 차 다항식이니 최대 $2$ 개의 해가 있음)
이에 따라서,
$|S_{i_0} \setminus (\cup_{j = 1}^{\Delta} S_{i_j})|$
$\geq |S_{i, 0}| - \sum |S_{i_0} \cap S_{i_j}|$
$\geq q - 2 \Delta \geq \Delta \geq 1$ 이 만족한다. $\blacksquare$
위 증명을 이차가 아닌 삼, 사차식에 대해서 하는 식으로 조금씩 다른 결과를 얻을 수도 있다.
3.2. Kuhn-Wattenhofer Coloring Algorithm
3.1의 결과를 통해서 우리는 $O(\log^* n)$ 번의 라운드 이후 $O(\Delta^2)$-coloring을 얻을 수 있다. 이를 통해서, $O(\Delta^2 + \log^* n)$ 번의 라운드로 $(\Delta + 1)$-coloring을 얻는 것은 어렵지 않다. $k \geq \Delta + 2$ 개의 색으로 칠해진 그래프가 주어질 때, 한 라운드에서 $k$ 번 색에 대해 남는 색을 칠하는 방식으로 색의 최댓값을 줄일 수 있기 때문이다. (이 행위를 one-by-one color reduction 이라고 부르자.)
여기에 좋은 아이디어 하나를 추가하여 $O(\Delta \log \Delta + \log^* n)$ 라운드 알고리즘으로 최적화를 할 수 있다.
Theorem 6. 최대 차수가 $\Delta$ 이며 $k \geq \Delta + 2$ 개의 색으로 칠해진 그래프가 주어졌을 때, $O(\Delta \log (\frac{k}{\Delta + 1}))$ 번의 라운드 이후 $(\Delta + 1)$-coloring을 얻을 수 있다.
Proof of Theorem 6. $k \leq 2\Delta + 1$ 인 경우 one-by-one color reduction 을 $k - \Delta - 1$ 번 반복하면 된다. 고로 $k \geq 2 \Delta + 2$ 임을 가정하자.
각 색 ${1, 2, \ldots, k}$ 를, 크기가 $2\Delta + 2$ 인 버킷 $\lfloor \frac{k}{2\Delta + 2} \rfloor$ 개로 나눈다 (마지막 버킷의 크기는 $[2\Delta + 2, 4\Delta + 3]$ 범위일 수 있다.) 이제 각각의 버킷을 기준으로 one-by-one color reduction 을 Parallel하게 수행하자. 다시 말해, 각 노드에 대해서, 예를 들어 해당 노드가 색깔 버킷의 $2\Delta + 2$ 번째 원소라면, 인접한 노드 중 같은 색깔 버킷에 속한 노드들을 전부 보고, 해당 노드에 등장하지 않는 남는 색으로 자신의 색을 바꾸는 식이다. 마지막 버킷의 크기가 $4\Delta + 3$ 이니, 이를 $3\Delta + 2$ 번 반복하면 각 버킷이 $\Delta + 1$ 개의 색을 가지게 되며, 서로 다른 색깔의 수가 반으로 줄어든다. 이를 $k \leq 2\Delta + 1$ 이 될 때까지 반복하면 된다 $\blacksquare$
이제 다음과 같은 방식으로 $O(\Delta \log \Delta + \log^* n)$ 번의 라운드로 $(\Delta + 1)$-coloring을 얻을 수 있다.
- Theorem 5로 $O(\log^* n)$ 번의 라운드 이후 $O(\Delta^2)$-coloring을 얻는다.
- Therorem 6으로 $O(\Delta \log (\frac{c\Delta^2}{\Delta + 1})) = O(\Delta \log \Delta)$ 번의 라운드 이후 $(\Delta + 1)$-coloring을 얻는다.
3.3. Kuhn's Algorithm via Defective Coloring
마지막으로, $O(\Delta + \log^* n)$ 번의 라운드로 $(\Delta + 1)$-coloring 을 얻는 알고리즘을 소개하고 이 장을 마친다. 이 알고리즘은 그동안의 알고리즘과 다르게 중간 과정에서 coloring이 올바르지 않을 수 있다 라는 큰 차이가 있다.
Definition. 어떠한 Coloring이 $d$-defective $k$-coloring 이라는 것은, 모든 색 $q \in [k]$ 에 대해서 해당 색을 가진 induced subgraph의 차수가 최대 $d$ 라는 것이다. (일반적인 Coloring은 $d = 0$ 을 만족한다.)
핵심 Lemma는, 어떠한 defective coloring이 주어질 때, $d$ 를 조금 올리는 대가로 $k$ 를 많이 줄이는 방법이 존재한다는 것이다.
Lemma 7.1. 최대 차수가 $\Delta$ 인 그래프에 대한 $d$-defective $k$-coloring 과 인자 $d^\prime \geq d$ 가 주어질 때, 한 번의 라운드를 거쳐 $d^\prime$-defective $k^\prime$ 을 얻을 수 있다. 이 때 $k^\prime = O((\frac{\Delta - d}{d^\prime - d + 1})^2 \log k)$ 를 만족한다.
Proof of Lemma 7.1. 만약 다음과 같은 함수 $f : [k] \rightarrow 2^{[k^\prime]}$ 이 존재한다고 하자:
- 모든 $n_0 \in [k]$ 에 대해 $|f(n_0)| = \Omega((\frac{\Delta - d}{d^\prime - d + 1}) \log k)$
- 모든 $n_0, n_1 \in [k], n_0 \neq n_1$ 에 대해, $|f(n_0) \cap f(n_1)| = O(\log k)$
먼저 이러한 함수가 존재할 경우 Lemma 7.1이 참임을 증명한다. 각 정점에 대해서, 해당 정점과 인접하면서 색이 같은 노드들을 잠시 무시한다. $f$ 를 사용하여 정점 $v$의 색을 어떠한 $[k^\prime]$ 의 부분 집합에 대응시키고, 이 부분 집합에서 인접한 노드들의 $f$ 에 최대 $d^\prime - d$ 번 속하는 수를 뽑아서 $v$ 의 새로운 색으로 둔다. 새로운 색이 존재하려면, $|f(n_0)| (d^\prime - d + 1) > (\Delta - d) \log k$ 을 만족해야 하는데, 위 조건에 따라서 이것이 만족되니, Lemma 7.1은 참이 된다.
이제 위와 같은 함수의 존재성을 probabilistic method를 사용하여 보인다. 충분히 큰 상수 $\alpha$ 에 대해 $p = \frac{d^\prime - d +1}{\alpha(\Delta - d_1)}$, $k^\prime = \frac{100}{p^2} \log k$ 이라 두고, $i\in [k]$ 에 대해 $f(i)$ 를, $[k^\prime]$ 에서 각 수를 독립적으로 확률 $p$ 로 샘플링한 함수라고 하자. 일단 첫 번째 성질을 증명한다:
- $E[|f(i)|] = pk^\prime = \frac{100}{p} \log k$
- Chernoff bound에 의해 $Pr[|f(i)| \leq \frac{50}{p} \log k] \leq e^{-12.5 / p \log k} \leq e^{-10 \log k}$
- 위를 Union bound로 묶으면, 모든 $i$ 에 대해 $|f(i)| \geq \frac{50}{p} \log k$ 일 확률이 $1-k^{-9}$ 이상
고로 WHP 첫 번째 성질이 성립한다. 두 번째 성질도 비슷하게 증명된다:
- $E[|f(i) \cap f(j)|] = p^2k^\prime = 100 \log k$
- $Pr[|f(i) \cap f(j)| \geq 200 \log k] \leq e^{-5 \log k}$
- 위를 Union bound로 묶으면, 모든 $i, j$ 에 대해 $|f(i) \cap f(j)| \geq 200 \log k$ 일 확률이 $1 - k^{-3}$ 이상
WHP 두 번째 성질이 성립한다. $\blacksquare$
Theorem 7. 최대 차수가 $\Delta$ 인 그래프에 대해 $O(\Delta + \log^* n)$ 번의 라운드를 거쳐 $(\Delta + 1)$-coloring을 찾을 수 있다.
Proof. Theorem 5의 알고리즘으로 $O(\log^* n)$ 번의 라운드 이후 $O(\Delta^2)$-coloring을 얻고 시작하자.
재귀적인 알고리즘을 사용한다. $T(\Delta)$ 를 $O(\Delta^2)$-coloring이 주어졌을 때 $O(\Delta + 1)$-coloring을 찾는 알고리즘의 시간 복잡도라고 하자. 대략적인 틀은, Defective coloring을 구하는 알고리즘을 통해서 $(\Delta / 2, O(1))$-defective coloring을 구하고, 각 색에 대한 induced subgraph에 대해서 재귀적으로 문제를 해결하는 식이다.
정확하게는 다음과 같다. Lemma 7.1을 한 번 반복하면, $(\frac{\Delta}{\log \Delta})$-defective $O(\log^3 \Delta)$-coloring을 얻을 수 있고, 한번 더 하면 $(\frac{\Delta}{\log \log \Delta})$-defective $O(\log^3 \log \Delta)$-coloring을 얻을 수 있고, 한번 더 하면 $(\frac{\Delta}{\log \log \log\Delta})$-defective $O(\log^3 \log \log \Delta)$-coloring을 얻을 수 있고.... 반복하면, $O(\log^*\Delta)$ 번의 반복 후 $(\frac{\Delta}{2})$-defective $O(1)$-coloring을 얻을 수 있다.
이제 우리는 $O(\log^*\Delta)$ 번의 라운드 후 $O(1)$ 개의 최대 차수가 $\Delta / 2$ 인 induced subgraph를 얻었다. 이제:
- Theorem 5의 알고리즘으로 각 subgraph에 대해 $O(\Delta^2)$ 초기 채색을 구해준다: $O(\log^* \Delta)$ (초기 $\log^* n$ 으로 최대 채색을 $O(\Delta^2)$ 로 바꿔줬기 때문에, $n$ 에 대한 dependency가 아니라 $\Delta$ 에 대한 dependency 이다.)
- 각각에 대해서 재귀적으로 문제를 해결한다: $T(\Delta / 2)$ (재귀적으로 parallel하게 하니 subproblem은 $O(1)$ 개가 아니라 $1$ 개다.)
- 이를 합치면 $O(\Delta)$-coloring을 얻으니, $O(\Delta)$ 번의 one-by-one color reduction을 수행해서 $\Delta + 1$ coloring을 얻는다: $O(\Delta)$
종합하면, $T(\Delta) = O(\log^* \Delta) + O(\log^* \Delta) + T(\Delta / 2) + O(\Delta) = O(\Delta)$ 가 된다. $\blacksquare$
3.4 Better algorithm?
놀랍게도 $(\Delta + 1)$-coloring을 $O(\Delta + \log^* n)$ 라운드에 구하는 것은 최적 알고리즘이 아니고, $O(\Delta^{1/2}\log^{5/2}\Delta + \log^* n)$ 번의 라운드로 $(\Delta + 1)$-coloring을 구하는 알고리즘도 존재한다. 아직 lower bound와 upper bound가 맞춰지지 않은 문제이고, 최근까지도 발전이 있었던 분야이니, 관심 있게 지켜볼만한 문제이다. 링크 건 알고리즘은 그렇게 어렵지 않다고 하니, 관심 있으면 읽어보는 것을 추천한다.
4. Network Decomposition
LOCAL model을 처음에 소개하면서 만약 그래프의 지름이 작은 경우 어떤 문제든 지름에 비례하는 라운드를 사용하여 해결할 수 있다는 것을 언급했다. 즉, 지름이 작은 그래프는 Distributed algorithm에게 쉬운 그래프 이다. 그래프 알고리즘에서 중요한 테마 중 하나는 일반적인 그래프를 쉬운 그래프들로 분해하여, 쉬운 그래프에서 푼 문제들을 결합하여 전체 문제를 푸는 테크닉이다. Distributed algorithm에서도 그러한 개념을 적용할 수 있다.
조금 더 구체적인 예시로는, $(\Delta + 1)$-coloring을 구하는 다음과 같은 Distributed algorithm을 생각해 보자. 다음 알고리즘은, 어떠한 인자 $c$ 에 대해서 $O(c)$ 번의 라운드로 $(\Delta + 1)$-coloring을 구한다.
- 그래프에서 랜덤한 독립 집합을 찾아서 지우는 것을 반복한다. 이것을 적은 라운드 안에 할 수 있다고 하고, 각 독립 집합을 $G_1, G_2, \ldots, G_c$ 라고 하자.
- 각 $G_i$ 마다 병렬적으로 Greedy하게 색을 아무거나 찾아준다. 병렬적으로 처리해도 괜찮다. 독립 집합이기 때문이다.
완전 그래프를 생각해 보면 $c = \Omega(n)$ 임을 쉽게 알 수 있다. 독립 집합은, induced subgraph의 각 컴포넌트의 지름이 $0$ 이하라는 강한 조건을 요구한다. 만약 induced subgraph의 컴포넌트의 지름이 $d$ 이하면 어떻게 될까? 위와 달라진 내용들을 볼드 체로 강조한다.
- 그래프에서 랜덤한, 지름이 적당히 작은 컴포넌트들의 합집합을 찾아서 지우는 것을 반복한다. 이것을 적은 라운드 안에 할 수 있다고 하고, 지운 정점들을 $G_1, G_2, \ldots, G_c$ 라고 하자.
- 각 컴포넌트의 정보를 $O(d)$ 번의 라운드로 모아준다.
- 각 $G_i$ 의 컴포넌트마다 병렬적으로 Greedy하게 색을 아무거나 찾아준다. 병렬적으로 처리해도 괜찮다. 문제가 생기려면 두 컴포넌트가 인접해야 하는데 그러면 컴포넌트가 아니다.
위 예시는 아래에서 설명할 내용을 대체적으로 요약하지만, 정확한 정의는 아니다. 이제 같은 내용을 엄밀하게 다시 짚고 넘어간다.
Definition (Strong Diameter Network Decomposition). 그래프 $G = (V, E)$ 가 주어질 때, $G$ 의 $(c, d)$-strong diameter network decomposition 은 $G$ 의 vertex-disjoint partition $G_1, G_2, \ldots, G_c$ 으로, 다음 성질을 가진다:
- 모든 $i$ 에 대해 $G_i$ 의 각 연결 컴포넌트의 지름이 최대 $d$ 이다.
Definition (Weak Diameter Network Decomposition). 그래프 $G = (V, E)$ 가 주어질 때, $G$ 의 $(c, d)$-weak diameter network decomposition은 $G$ 의 vertex-disjoint partition $G_1, G_2, \ldots, G_c$ 으로, 다음 성질을 가진다:
- 모든 $i$ 에 대해, $G_i$ 는 cluster $X_1, X_2, \ldots, X_l$ 로 분해된다. $X_j$ 는 $G_i$ 의 vertex partition이고, 서로 다른 $j \neq k$ 에 대해 $X_j, X_k$가 인접하지 않는다. $l$ 의 크기에 대한 제한은 없다.
- $X_j$ 의 서로 다른 두 정점은 $G$ 상에서 ($G_i$ 상이 아님!) 거리 $d$ 이하이다.
Weak Diameter Network Decomposition의 정의에서 non-adjacent하다는 것은, $G_i$ 의 한 연결 컴포넌트는 하나의 cluster $X_i$ 에 속한다는 뜻으로 이해할 수 있다. 여러 연결 컴포넌트가 하나의 cluster에 속할 수 있으나, 하나의 연결 컴포넌트가 여러 cluster에 속할 수는 없다. 어떠한 Strong Diameter Network Decomposition는, Weak Diameter Network Decomposition이기도 하다.
Therorem 8. $G$ 의 $(c, d)$-weak diameter network decomposition이 주어진다면, $O(cd)$ 라운드에 $G$ 의 $\Delta + 1$ coloring을 얻을 수 있다.
Proof. $G_1, G_2, \ldots, G_i$ 가 $(\Delta + 1)$-colored 되었을 때 $G_{i+1}$을 $O(d)$ 라운드에 $(\Delta + 1)$-coloring 한다. $G_{i + 1}$ 의 각각의 Cluster $X_j$ 에 대해, $v_j$ 를 $X_j$ 에서 번호가 가장 큰 노드로 정의하자. 그러한 $v_j$ 는 $O(d)$ 번의 라운드에 구할 수 있다 - $G$ 에서 거리가 $d$ 이하인 정점들을 모두 모은 후, 그 중 $X_j$ 에 속하며 자신보다 번호가 큰 노드가 있는지 확인할 수 있기 때문이다.
이제 그러한 $v_j$ 에서, 거리가 $d + 1$ 이하인 모든 정점들을 모으고 그 induced subgraph에 대한 정보들을 전부 모으자. 이 때 이 그래프는:
- $X_j$ 의 모든 정점들을 포함한다. (거리 $d$ 이하)
- $X_j$ 에 인접한 정점 중 다른 $X_k$ 에 속한 정점은 없다 (정의에 의해)
이제 $X_j$ 에 있는 정점들을 Greedy하게 칠해주면 $(\Delta + 1)$-coloring을 구할 수 있다. 다른 $X_j$ 들에 대해서도 이렇게 해 주어도, 어차피 서로 다른 $X_j, X_k$ 에서 인접한 노드가 없기 때문에 충돌이 일어날 일은 없다. $\blacksquare$
Network Decomposition의 퍼포먼스는 주어진 인자 $(c, d)$ 가 얼마나 작은지에 따라서 결정된다는 것을 알 수 있다. 이 단락에서는 Network Decomposition을 얻을 수 있는 세 가지 알고리즘을 소개한다. 세 알고리즘은 randomized되어 있는지, $(c, d)$ 가 얼마나 작은지, 구성에 얼마나 많은 라운드가 필요한지에 따라서 조금씩 달라진다.
4.1. Randomized Construction - $(O(\log n), O(\log n))$ in $O(\log^2n)$ rounds
Theorem 9. $n$ 개의 정점을 가진 그래프가 주어질 때 $c = O(\log n), d = O(\log n)$ 인 $(c, d)$ weak-diameter network decomposition을 $O(\log^2 n)$ 번의 라운드로 구할 수 있다.
Proof of Theorem 9. $G_1, G_2, \ldots, G_i$ 를 이미 구했다고 했을 때 $G_{i + 1}$ 을 어떻게 구하는 지 설명한다.
각 정점 $v$ 에 대해, 랜덤한 반지름 $r_u$ 를 Geometric distribution에서 샘플링한다. 구체적으로, 어떠한 $\epsilon \in (0, 1)$ 에 대해서, $y \geq 1$ 이 $r_u$ 로 뽑힐 확률 $Pr[r_u = y] = \epsilon(1 - \epsilon)^{y - 1}$ 이다. 이제 각 노드 $v$ 에 대해서, $Center(v)$ 를 $dist_G(u, v) \leq r_u$ 면서 번호가 가장 작은 $u$ 로 정의하자. 다시 말해, $u$ 에서 $r_u$ 크기의 공 을 그렸을 때, $v$ 를 덮는 공 중 번호가 가장 작은 공의 번호가 $u$ 가 된다. 이제 $G_i$ 를 다음과 같이 정의한다:
- $G_i$ 의 각 클러스터는 $Center(v)$ 가 같은 노드들의 집합이다.
- $dist_G(u, v) = r_u$ 인 노드들은 $G_i$ 에서 제외한다.
직관적으로 보았을 때, 이렇게 생각하면 좋다: $u = 1, 2, \ldots, n$ 순서대로 보면서, $r_u$ 크기의 공에 속하는 아직 체크되지 않은 노드들을 한 클러스터에 넣고 체크해준다. 이후 나중에 각 클러스터들을 돌 때, $dist_G(u, v) = r_u$ 인 노드들은 다른 클러스터와 인접할 가능성이 있다. 고로 이 노드들은 체크를 해제해 준다. 이렇게 하면 Parallelization이 안 되니, 여기서는 거꾸로 처리하면서 $\max r_u$ 라운드 안에 계산이 가능하게끔 한다.
이렇게 $G_{i+1}$ 을 구하는 알고리즘의 설명이 끝났다. 아래 네 가지 사실을 증명하면 Theorem 9의 증명이 종료된다.
- Lemma 9.1. 위와 같은 Decomposition을 구하면 인접한 노드가 다른 클러스터에 속하지 않는다. (인접 조건 증명)
- Lemma 9.2. 위와 같은 Decomposition은 WHP 같은 클러스터의 두 정점 간의 최대 거리가 $O(\log n / \epsilon)$ 이다. ($d = O(\log n)$)
- Lemma 9.3. 위와 같은 Decomposition은 각 $i$ 에 대해 $O(\log n / \epsilon)$ 시간에 계산 가능하다. ($O(c \log n)$ round suffices)
- Lemma 9.4. 위와 같은 Decomposition은 $O(\log_{1/\epsilon} n)$ 번 안에 모든 노드를 어떠한 $G_i$ 에 종속되게 한다. ($c = O(\log n)$)
Proof of Lemma 9.1. 귀류법으로, 인접한 노드 $u, v$ 가 다른 클러스터에 속하는 일이 있었다고 하자. WLOG $Center(u) < Center(v)$ 라고 할 때, $dist_G(Center(u), v) \leq dist_G(Center(u), u) + 1 \leq r_{Center(u)}$ 로, $v$ 는 $u$ 와 같은 클러스터에 속했어야 한다. 고로 가정에 모순이다.
Proof of Lemma 9.2. 정의에 의해 $r_u > \frac{10 \log n}{\epsilon}$ 일 확률은 $n^{-8}$ 이하이다. 고로 $\max r_u > \frac{10 \log n}{\epsilon}$ 일 확률도 Union bound에 의해 $n^{-7}$ 이하이다. 같은 클러스터의 두 정점 간 최대 거리가 $2 \max r_u$ 이니, WHP 최대 거리는 $\frac{20 \log n}{\epsilon} = O(\frac{\log n}{\epsilon})$ 이다.
Proof of Lemma 9.3. 결국 자신을 덮는 최소 인덱스의 공을 찾아야 하는데, 이를 위해서는 $\max r_u = O(\frac{\log n}{\epsilon})$ 범위의 정점 정보를 전부 수집하면 된다. 고로 그 만큼의 라운드가 필요하다.
Proof of Lemma 9.4. 각 노드가 매 라운드에서 클러스터링되지 않을 확률이 최대 $\epsilon$ 이라는 것을 증명하면 Lemma 9.4가 자연히 따라온다. 고로 이를 증명한다.
$v$ 가 클러스터링 되지 않을 확률은, 모든 $u$ 에 대해서 $Center(v) = u$ 이면서 $r_u = dist_G(v, u)$ 일 확률의 합과 동일하다. $Center(v) = u$ 임이 정해졌을 때, $v$ 가 클러스터링 되지 않을 확률을 세기 위해 다음과 같은 확률 변수를 도입하자:
- $\mathcal{E}_1 = (r_u = dist_G(v, u))$
- $\mathcal{E}_2 = (r_u \geq dist_G(v, u))$
- $\mathcal{E}_3 = (Center(v) = u) = (\forall i < u, r_i < dist_G(v, i))$
이 때 $\mathcal{E}_3$ 은 $\mathcal{E}_1, \mathcal{E}_2$ 와 독립이다. 이제 확률을 써 보면
$\frac{Pr[\mathcal{E}_1 \cap \mathcal{E}_3]}{Pr[\mathcal{E}_2 \cap \mathcal{E}_3]}$
$=\frac{Pr[\mathcal{E}_3] \times Pr[\mathcal{E}_1 | \mathcal{E}_3]}{Pr[\mathcal{E}_3] \times Pr[\mathcal{E}_2 | \mathcal{E}_3]}$
$=\frac{ Pr[\mathcal{E}_1 | \mathcal{E}_3]}{Pr[\mathcal{E}_2 | \mathcal{E}_3]}$
$=\frac{ Pr[\mathcal{E}_1]}{Pr[\mathcal{E}_2]}$
$=\epsilon$
$u$ 가 무관하게 무조건 확률은 $\epsilon$ 이니 전체 확률도 $\epsilon$ 이다.
고로 Theorem 9가 증명된다. $\blacksquare$
4.2. Deterministic Construction - $(2^{O(\sqrt{\log n})}, 2^{O(\sqrt{\log n})})$ in $2^{O(\sqrt{\log n})}$ rounds
Theorem 10.1. $n$ 개의 정점을 가진 그래프가 주어질 때 $c = 2^{O(\sqrt{\log n})}, d = 2^{O(\sqrt{\log n})}$ 인 $(c, d)$ strong-diameter network decomposition을 $2^{O(\sqrt{\log n})}$ 번의 라운드로 구할 수 있다.
여기서는 Theorem 10.1 보다 조금 더 약한 대신 간단한 버전을 증명한다.
Theorem 10. $n$ 개의 정점을 가진 그래프가 주어질 때 $c = 2^{O(\sqrt{\log n \log \log n})}, d = 2^{O(\sqrt{\log n\log \log n})}$ 인 $(c, d)$ weak-diameter network decomposition을 $2^{O(\sqrt{\log n\log \log n})}$ 번의 라운드로 구할 수 있다.
이를 위해 새로운 정의인 ruling sets 를 도입한다.
Definition (Ruling Sets). 그래프 $G = (V, E)$ 와 정점 부분집합 $W \subseteq V$ 에 대해, $(G, W)$의 $(\alpha, \beta)$-ruling set 은 다음 조건을 만족하는 $S \subseteq W$ 를 뜻한다:
- 임의의 $u, v \in S$ 에 대해 $dist_G(v, u) \geq \alpha$ ($\alpha$-independent)
- 임의의 $v \in W$ 에 대해, $dist_G(v, u) \leq \beta$ 인 정점 $u \in S$ 가 존재함 ($\beta$-dominating)
예를 들어, $W = V$ 라고 하면, $V$ 의 임의의 maximal independent set은 $(2, 1)$-ruling set이 된다. 또한, $G^k = (V, E^k)$ 를 $G = (V, E)$ 에서 두 정점 간의 거리가 $k$ 이하일 때 간선을 이은 그래프라고 하면, $G^k$ 의 임의의 maximal independent set은 $(k+1, k)$-ruling set이 된다.
Lemma 10.2. 정점이 $n$ 개인 그래프 $G = (V, E)$ 와 정점 부분집합 $W \subseteq V$, 정수 $k$ 에 대해, $(G, W)$의 $(k, k \log n)$-ruling set 을 $O(k \log n)$ 라운드에 찾을 수 있다.
Proof. 분할 정복을 사용한다. (편의상 루트의 부분문제만 설명한다. 더 낮은 깊이의 부분문제도 똑같은 방식으로 하면 된다.)
$W_0 \subseteq W$ 를 정점 번호가 짝수인 부분집합, $W_1 \subseteq W$ 를 홀수인 부분집합이라고 하자. $W_0$ 의 $(k, k (\log n - 1))$-ruling set, $W_1$ 의 $(k, k (\log n - 1))$-ruling set을 각각 병렬로 구하고 이들을 $S_0, S_1$ 이라고 하자. $S$ 에 $S_0$ 의 모든 원소를 추가하고, $S_1$ 중 거리 $k$ 반경에 $S_0$ 의 원소가 없는 원소들만 $S$ 에 추가해 준다. 이 작업은 $O(k)$ 번의 라운드로 가능하다.
이 작업이 $k$-independent를 보장한다는 것은 쉽게 알 수 있다. 또한, $W_0$ 의 원소들에 대해서는 $S_0$ 이 모두 $S$ 에 들어가니 $k (\log n - 1)$ 범위 안에 여전히 $u \in S$ 가 존재한다. $W_1$ 의 원소들 중, 원래 $k (\log n - 1)$ 범위 안에 들어가던 원소 $S_1$ 이 사라진 원소들은, 그 원소에서 거리 $k$ 이하에 $S_0$ 의 원소가 존재한다는 것을 알 수 있다. 고로 $k (\log n - 1) + k = k \log n$ 범위 안에 $S$ 의 원소를 찾을 수 있다. $\blacksquare$
Proof of Theorem 10. 어떤 파라미터 $d$ 를 설정하자. 정확한 값은 마지막에 고를 것이다.
정점 집합 $V$ 를 차수가 $d$ 이상인 정점 집합 $H$, $d$ 미만인 정점 집합 $L$ 로 분할한 후, Lemma 10.2를 이용하여 $(G, H)$ 의 $(3, O(\log n))$-ruling set $S$ 를 $O(\log n)$ 시간에 찾는다. 이제 모든 $v \in V$ 에 대해서, 만약 $O(\log n)$ 거리 안에 $S$ 에 속하는 정점이 하나라도 있다면, 그 중 가장 인덱스가 작은 정점을 $Center(v)$ 라고 하자. 이렇게 할 경우
- $Center(v)$ 가 같은 정점들은 서로 간의 거리가 $O(\log n)$ 이다.
- 임의의 정점 $x \in S$ 에 대해 $Center(v) = x$ 인 정점이 최소 $d+1$ 개이다. ($x$ 와 그에 인접한 정점들이 모두 $Center(v) = x$ 이기 때문이다.)
- $Center(v)$ 가 정의되지 않은 정점들의 차수는 $d-1$ 이하이다.
$Center(v)$ 가 정의되지 않은 정점들에 대해 $d$-coloring을 $O(d + \log^* n)$ 라운드에 구하자 (Theorem 7). 이제 Network decomposition의 원소 $G_1, G_2, \ldots, G_d$ 를 만드는데, $G_i$ 는 색이 $i$ 며 $Center(v)$ 가 정의되지 않은 정점들의 집합이다. $G_i$ 는 독립 집합이니, 당연히 Network decomposition의 가정을 만족한다.
이제 $Center(v)$ 가 정의된 정점이 남는다. 이들은 서로간의 거리가 $O(\log n)$ 이니, 이들을 하나의 정점으로 합쳐 주자 (contract). 간선은 일반적인 contraction과 동일하게, $Center(v)$ 가 다른 정점 $Center(w) \neq Center(v)$ 이 인접한 경우, $Center(v), Center(w)$ 사이에 간선을 이어주자. 이를 통해, 정점의 개수는 $|S| \leq \frac{n}{d+1}$ 이 된다. 이 그래프에 대해서 재귀적으로 동일한 방법으로 Network decomposition을 만들어주고, $G_i$ 를 만들 때는 합쳐진 정점의 원래 원소들을 풀어서 넣어준다. 맨 첫 문제를 깊이 $1$ 이라고 둘 때, 깊이 $i$ 의 문제가 기존과 다른 점은 다음과 같다:
- $Center(v)$ 가 같은 정점들의 거리는 서로 간의 거리가 $O((\log n)^i)$ 이다.
- Ruling set을 구하는데 $O((\log n)^i)$ 시간이 든다. 실제 Contraction을 구할 수 없기 때문에, 인접한 정점 이 무엇인지를 알기 위해서라도 해당 거리만큼을 탐색해야 하기 때문이다. Coloring에서도, 비슷한 이유로 $O((\log n)^i (d + \log^* n))$ 시간이 든다.
- $Center(v)$ 가 정의되지 않은 정점들에 대해 $d$-coloring을 구했을 때 그것이 독립 집합이 아닐 수 있다. 합쳐진 정점의 원래 집합에 대해서 동일한 색이 칠해지기 때문이다. 대신, 합쳐진 정점의 지름이 $O((\log n)^i)$ 로 bound되니, 결국 이렇게 구할 경우 각 연결 컴포넌트의 반지름은 $O((\log n)^i)$ 이 된다.
이를 모아보면 우리는 $d \times O(\log n)^{\log_d n}$ 번의 라운드에 $(d \log_d n, O(\log n)^{\log_d n})$-strong diameter network decomposition 을 얻을 수 있다. $d = 2^{O(\sqrt{\log n \log \log n})}$ 으로 두면, 위 조건을 만족함을 볼 수 있다. $\blacksquare$
4.3. Deterministic Construction - $(\log n, \log n)$ in $O(\log^8 n)$ rounds
아래 Theorem은 2020년 Rozhon, Ghaffari에 의해 발견된 알고리즘으로, network decomposition을 poly(log n) 시간에 계산할 수 있는 첫 번째 알고리즘이다. 여기서 다루는 알고리즘은 다른 언급이 없어도 Deterministic하다.
Theorem 11. $n$ 개의 정점을 가진 그래프가 주어질 때 $c = O(\log n), d = O(\log n)$ 인 $(c, d)$ strong-diameter network decomposition을 $O(\log^8 n)$ 번의 라운드로 구할 수 있다.
알고리즘은 크게 세 가지 Lemma로 구성된다.
Lemma 11.1 (Clustering Lemma) 각 정점에 $b = O(\log n)$ 비트의 인덱스가 매겨진 그래프 $G = (V, E)$, 그리고 정점 부분집합 $S \subseteq V$ 가 주어졌을 때, $O(\log^6 n)$ 번의 라운드 안에 다음과 같은 $S^\prime \subseteq S$ 를 찾을 수 있다:
- $|S^\prime| \geq |S| / 2$
- induced subgraph $G[S^\prime]$ 가 cluster $X_1, X_2, \ldots, X_l$ 로 분해된다. $X_j$ 는 $G_i$ 의 vertex partition이고, 서로 다른 $j \neq k$ 에 대해 $X_j, X_k$가 인접하지 않는다
- 각 cluster의 임의의 두 정점간 거리는 $O(\log^3 n)$ 이하이다.
Lemma 11.2. $n$ 개의 정점을 가진 그래프가 주어질 때 $c = O(\log n), d = O(\log^3 n)$ 인 $(c, d)$ strong-diameter network decomposition을 $O(\log^7 n)$ 번의 라운드로 구할 수 있다.
Lemma 11.3. $N$ 개의 정점을 가진 그래프에 대해 $(C(N), D(N))$ weak-diameter network decomposition을 $T(N)$ 라운드에 구하는 deterministic algorithm이 존재한다면, $T(n) \times O(\log n) + O(C(n) D(n) \log^2 n)$ 라운드에 때 $c = O(\log n), d = O(\log n)$ 인 $(c, d)$ strong-diameter network decomposition을 구할 수 있다.
Lemma 11.1 이 참이라면 $S = V$ 에서 시작해서 $S = S - S^\prime$ 을 반복하는 식으로 Lemma 11.1의 알고리즘을 $O(\log n)$ 번 반복하면 Lemma 11.2를 바로 증명할 수 있다. 또한, Lemma 11.2와 Lemma 11.3 을 결합하면 Theorem 11 역시 바로 유도된다. 고로, Lemma 11.1과 Lemma 11.3을 증명하는 것이 필요하다.
4.3.1 Proof of Lemma 11.1
알고리즘은 $b = O(\log n)$ 개의 단계로 구성된다. 맨 처음 $S$ 의 모든 노드는 생존 상태로 분류되고, $S^\prime$ 을 구성하는 과정에서 일부 노드들은 사망 상태가 된다. 각 단계를 $0, 1, \ldots, b - 1$ 로 인덱싱할 때, $i \in [0, b]$ 에 대해 $S^\prime_i$ 를 $i-1$ 번째 단계가 끝난 이후의 생존 상태 의 정점이라고 하자. 특별히 $S^\prime = S_b^\prime$ 을 모든 단계가 끝난 이후 생존 상태의 정점으로 정의한다. 이것이 우리의 최종 output이 되기도 한다.
각각의 노드 $v$ 에 대해서 $b$ 비트 이진 문자열 $l(v)$ 를 정의한다. 처음에 $l(v)$ 는 $v$ 의 인덱스의 이진 표현인데, 이 라벨은 시간이 지나면서 바뀔 수 있다. 임의의 $b$-비트 라벨 $L \in {0, 1}^b$ 에 대해 $S_i^\prime(L) \subseteq S_i^\prime$ 을 $v \in S_i^\prime, l(v) = L$ 을 만족하는 생존 상태의 노드 집합이라고 하고, 이를 cluster 라고 부른다. 비슷하게, 임의의 $c(\leq b)$ 라벨 $L \in {0, 1}^c$ 에 대해 $S_i^\prime(L) \subseteq S_i^\prime$ 을 $v \in S_i^\prime$ 이며 $l(v)$ 의 길이 $c$ suffix 가 $L$ 인 생존 상태의 노드 집합이라고 하자.
사실 이진 문자열 부분은 formality를 위해서 굉장히 어렵게 쓰여 있지만, 그냥 홀짝으로 분할 정복을 한다는 뜻이다. 아래에서 보면, 결국 알고리즘은 정점의 번호를 홀짝으로 나누고, 홀짝 간의 간선을 없앤 다음에, 각 독립된 부분문제를 푸는 식으로 진행될 것이다. 이렇게 보면 길이 $c$ 의 suffix가 같다는 것도 그냥 현재 깊이의 한 부분문제를 푼다는 이야기이다.
알고리즘은 $i$ 번째 단계가 끝난 이후 다음과 같은 조건을 항상 만족시킨다 (invariant):
- 임의의 길이 $i+1$ 의 문자열 $Y$ 에 대해서, $S^\prime_i(Y) \subseteq S^\prime_i$ 는 $S_i^\prime \setminus S_i^\prime(Y)$ 의 어떤 노드와도 인접하지 않는다. 다시 말해 $S_i^\prime(Y)$ 는 induced subgraph $G[S_i^\prime]$ 의 어떠한 연결 컴포넌트의 합집합이다.
- 임의의 라벨 $L \in {0, 1}^b$ 에 대해 $S_i^\prime(L)$ 안에 있는 임의의 두 정점은 $G$ 상의 거리가 $iR$ 이하이다. 이 때 $R = O(\log^2 n)$ 이다.
- $|S^\prime_{i+1}| \geq |S_i^\prime|(1- 1/2b)$ 이다.
$b-1$ 번째 단계가 끝난 이후 각각의 $S_i^\prime$ 은 Cluster를 이루며, 같은 Cluster의 임의의 두 정점은 $G$ 상의 거리가 $O(\log^3 n)$ 이다. 마지막으로, $|S^\prime_b| \geq |S_i^\prime|(1 - 1/2b)^b \geq |S|/2$ 를 만족한다. 고로, 위와 같은 invariant를 유지시켜 줄 수 있는 귀납적 알고리즘이 존재한다면 Lemma 11.1이 증명된다.
$i$ 번째 단계에서 알고리즘은 각 정점을 라벨 $l(v)$ 의 $i$ 번째 비트가 $0$ 인지 $1$ 인지, 그리고 길이 $i$ 의 suffix가 어떻게 되어 있는지에 따라서 분류한다. 즉, 모든 길이 $i$ 의 비트스트링 $Y$ 에 대해 $S_i^\prime(0Y), S_i^\prime(1Y)$ 을 구하는 것이다. (앞에서 얘기했지만 그냥 당연한 부분문제 정의이다. 용어가 어려울 뿐이다) $i$ 번째 비트가 $0$ 인 노드를 파란 노드라고 하고 $1$ 인 노드를 빨간 노드라고 하자. 개괄적으로, $i$ 번째 단계에서는 다음과 같은 일들이 일어난다.
- 빨간 노드의 일부를 사망 상태로 바꾼다.
- 빨간 노드의 일부를 파란 노드로 바꾼다.
이 과정에서 빨간 노드와 파란 노드를 잇는 정점이 없도록 하면, 각 부분문제가 독립이 되어서 재귀적으로 계속 내려갈 수 있다. 맨 앞 invariant와 같이 생각해 보면:
- 초기 subproblem은 어떠한 연결 컴포넌트의 합집합이었다. 여기서 빨간 노드와 파란 노드를 잇는 간선을 다 없애면, 하위 subproblem 역시 이것이 유지된다.
- 초기 weak-diameter는 당연히 0이다. 빨간 노드가 파란 노드로 바뀌면서 각 클러스터가 조금씩 커질 수 있다. 아래 알고리즘에서는 이것을 적당히 $iR$ 이내로 bound시켜야 한다.
- 빨간 노드를 많이 죽이지 않아야 한다.
이제 구체적으로 각 단계를 설명한다. 각 단계는 $R = 10 b \log n = O(\log^2 n)$ 개의 스텝으로 구성되며, 각 스텝은 $O(\log^3 n)$ 번의 라운드로 구성된다. 고로, 각 단계는 $O(\log^5 n)$ 개의 라운드로 구성되며 이는 전체 라운드가 $O(\log^6 n)$ 이라는 Lemma 11.1의 statement와 일치한다. 매 스텝에서, 빨간 노드는 임의의 인접한 파란 노드를 골라, 해당 노드가 있는 cluster에 합류하겠다는 메시지를 보낸다 (합류한다는 것은 해당 노드의 라벨을 그대로 쓰겠다는 뜻이다). 만약 인접한 파란 노드가 없다면 아무것도 하지 않는다.
이 때 각 파란 노드들의 cluster $A$ 들은 다음 두 가지 중 하나를 선택한다:
- 만약 해당 cluster에 들어오려고 하는 빨간 노드의 수가 $|A| / 2b$ 이하라면, 어떤 조건도 받아들이지 않으며, 요청한 모든 빨간 노드들을 죽인다. 그리고, $A$ 는 이 단계에서 더 이상 참여하지 않는다.
- 만약 해당 cluster에 들어오려고 하는 빨간 노드의 수가 $|A| / 2b$ 초과라면, 모든 조건을 받아들이고 요청한 빨간 노드들을 자신과 같은 라벨의 파란 노드로 바꾼다. $A$ 의 weak-diameter는 이 과정에서 최대 $2$ 커질 수 있다. 인접한 노드들이 들어왔기 때문이다.
이 한번의 스텝은 $O(\log^3 n)$ 라운드에 해결할 수 있다 - invariant에 의해 각 파란 노드의 weak diameter는 $O(\log^3 n)$ 이고, 고로 위 요청을 받아들이는데도 그 만큼의 시간이 필요하다. 몇 가지 사실을 관찰하자.
- 각 단계의 스텝은 최대 $4b \log n$ 번 반복된다. $A$ 가 커지는 속도는 $1+1/2b$ 보다 크고, $(1 + 1/2b)^{4b \log n} > n$ 이기 때문이다. 이에 따라 클러스터의 weak-diameter도 최대 $8b\log n$ 증가한다.
- 클러스터 $A$ 가 스텝에 더이상 참여하지 않는 순간이 된다면, 요청한 모든 빨간 노드들을 죽이기 때문에, 빨간 노드와 인접하지 않는다.
- 매 단계 각 subproblem $S_i^\prime(Y)$ 에서는 최대 $\frac{1}{2b} |S_i^\prime(Y)|$ 만큼의 노드가 죽는다. 파란 노드의 cluster가, 자신 크기의 $\frac{1}{2b}$ 이하의 빨간 노드를 죽이고 사라지기 때문이다. 즉, subproblem에서 죽는 노드의 수는 subproblem의 파란 노드의 수의 $\frac{1}{2b}$ 만큼이고 결국 전체 노드의 $\frac{1}{2b}$ 이하이다.
이 관찰들을 통해서 위 invariant들이 모두 성립함을 볼 수 있고 증명이 종료된다. $\blacksquare$
4.3.2 Proof of Lemma 11.3
$G^\prime$ 을, $G$ 와 정점 집합이 동일하고, 거리가 $10 \log n$ 이하인 두 정점 간에 간선이 이어진 새로운 그래프라고 하자. $G^\prime$ 은 $O(\log n)$ 라운드에 만들 수 있으며, $G^\prime$ 에서 $T(n)$ 번의 라운드로 weak-diameter network decomposition을 구할 수 있다. 이 decomposition은 $C(n)$ 개의 집합으로 이루어졌고, decomposition을 이루는 클러스터의 weak-diameter가 $10 D(n) \log n$ 이하이다.
이 decomposition의 $C(n)$ 개의 subgraph $G_i$ 를 순서대로 보면서, 새로운 network decomposition을 만들자. 각 $G_i$ 의 클러스터에 대해, 대표 정점을 $10 D(n) \log n$ 라운드에 찾아준 후, 클러스터의 임의의 노드에서 $\log n$ 거리 안에 있는 노드들을 모두 찾아주자. 이 때 각 클러스터에서 찾는 노드들은 다른 클러스터의 노드들을 포함하지 않는다. 만약 포함한다면 $G^\prime$ 에서 인접한 노드들이 다른 클러스터에 있다는 가정에 모순이기 때문이다.
이제 각 클러스터에서 이렇게 찾아준 서브그래프들에 대해서 앞과 비슷한 스텝을 수행한다. 찾은 서브그래프의 임의의 정점 $v$ 를 고르고 초기 $S = {v}$ 라고 두자. 매 단계에, $S$ 에 있는 노드들과 인접한 노드들의 수가 $S$ 의 크기 이상이라면, $S$ 에 인접한 노드들을 모두 넣어주고, 그렇지 않다면 종료한다. 종료한 이후, $S$ 와 그에 인접한 모든 노드들을 지워준다. 이것을, 서브그래프의 모든 노드들이 소진될 때까지 반복한다. (Iterative하는 것이 맞다. 느리다고 생각할 수 있으나, 앞에서 $\log n$ 거리의 노드들을 모두 찾은 이후에 하는 것이니 상관없다.)
각 subgraph마다 이것을 반복하면, $10 C(n) D(n) \log n$ 라운드에 각 $G_i$마다 적당한 $S$ 를 찾는다. 이들을 $S_i$ 라고 하면, 다음 사실을 관찰할 수 있다.
- $\sum |S_i| \geq n / 2$ 이다. 어떠한 노드가 $S_i$ 에 들어가지 못했다는 건 인접한 노드로서 지워졌다는 것을 의미하는데, 이러한 노드들의 수는 $S_i$ 의 수 이하이다.
- 서로 다른 두 클러스터 $S_i, S_j$ 의 두 노드가 인접하지 않는다. 알고리즘이 인접한 노드를 지웠기 때문이다.
- 각 $S_i$ 의 지름이 $2 \log n$ 이하이다. 클러스터의 크기가 $\log n$ 번만 성장하기 때문이다.
고로, 이 알고리즘을 $\log n$ 번 반복하면 Lemma 11.3이 증명된다.
5. Maximal Independent Set
지금까지 Graph Coloring을 논할 때 $(\Delta+1)$ coloring에 집중했듯이, Independent Set을 논할때도 여기서는 maximum independent set이 아닌 maximal independent set을 논한다. 이제부터는 편의상 maximal independent set을 MIS라고 부른다.
사실 MIS 문제는 단순히 independent set을 구한다는 관점 이상의 의미가 있다. 예를 들어, maximal matching은 line graph에서의 maximal independent set이기 때문에 MIS를 구하는 distributed algorithm은 maximal matching도 구할 수 있다. 조금 더 신기한 것은, MIS를 구하는 distributed algorithm으로 $(\Delta+1)$ coloring도 구할 수 있다는 것이다.
Lemma. MIS를 $T(N)$ 라운드에 구하는 알고리즘이 존재한다면, 최대 차수가 $\Delta$ 인 그래프의 $(\Delta+1)$-coloring을 $T(N(\Delta+1))$ 라운드에 구하는 알고리즘이 존재한다.
Proof. 그래프 $G$ 가 주어졌을 때, $G$ 를 $(\Delta + 1)$ 번 복사하고, 각 정점 $i$ 에 대해서 $(\Delta+1)$ 개의 복사본을 클리크로 묶는다. 아래 사진을 참고하라:
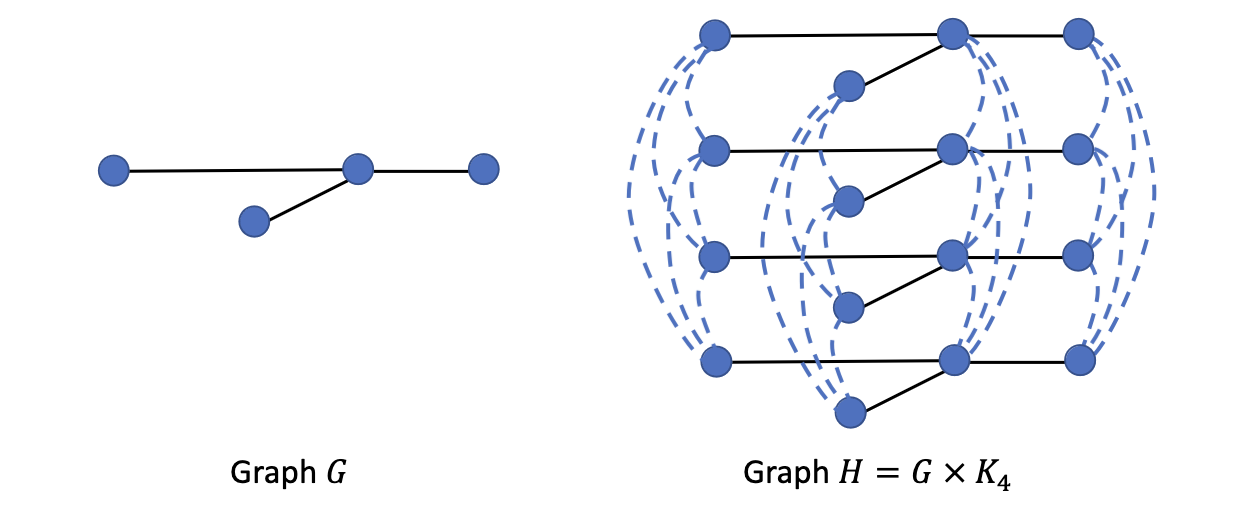
이 그래프에서 MIS를 찾으면, $i$ 번 정점의 복사본은 많아야 한 개 선택된다. 각 정점의 복사본이 클리크를 이루기 때문이다. 만약 $i$ 번 정점의 복사본이 $0$ 개 선택되었다고 하자. 이 정점에 인접한 정점의 수는 최대 $\Delta$ 개이니, 복사본 중 인접한 정점이 전혀 선택되지 않은 복사본이 존재한다. 이 복사본의 정점을 고르지 않으면 maximality에 모순이니, $i$ 번 정점의 복사본은 정확히 한 개 선택된다. 이제 선택된 복사본의 번호를 color로 배정하면, 이것이 올바른 $(\Delta+1)$-coloring임을 볼 수 있다. $\blacksquare$
이제 다음에서 MIS를 $O(\log n)$ 번의 라운드로 구하는 알고리즘에 대해 논의한다. 위 Lemma에 의해, 이 알고리즘을 사용하면 $(\Delta+1)$-coloring 역시 $O(\log n)$ 번의 라운드로 구할 수 있음을 볼 수 있다.
MIS는 여러 문제를 일반화하는 문제지만, 의외로 알고리즘은 아주 간단하다:
Definition (Luby's MIS Algorithm): 알고리즘은 매 반복에 두 번의 라운드를 사용한다:
- 첫 번째 라운드에서 각 노드 $v$ 는 랜덤한 실수 $r_v \in [0, 1]$ 을 골라서 인접한 노드에게 보낸다. 이후 $v$ 는 주변 모든 인접한 노드 $w$ 가 $r_w < r_v$ 를 만족하면 MIS에 들어간다.
- 두 번째 라운드에서, 자신 혹은 자신에 인접한 노드가 MIS에 들어갔다면 해당 노드가 삭제된다.
Theorem 12. Luby's Algorithm은 MIS를 높은 확률로 $O(\log n)$ 라운드에 구한다.
이를 증명하는 핵심 Lemma는 다음과 같다. 이 Lemma가 있으면 Theorem의 증명은 쉽다.
Lemma 12.1. $m$ 개의 간선이 있는 그래프에서 Luby's Algorithm을 한 반복 돌렸을 때, 남은 간선 수의 기댓값은 $m/2$ 이하다.
Proof of Lemma 12.1. 특정 간선 $(u, v)$ 가 주어질 확률을 분석해 보자. $u$ 가 지워진다는 것은, $u$ 혹은 그에 인접한 어떠한 정점이 MIS에 들어갔다는 것이다. 어떠한 정점 $w$ 가 MIS에 들어갈 확률은 $\frac{1}{deg(w) + 1}$ 인데, $u$ 혹은 그에 인접한 정점이 MIS에 들어갈 확률을 계산하기 위해 단순히 이를 합할 수는 없다. 고로, $u$ 가 지워진다는 것을, $u$ 에 인접한 노드들 중 $r_w$ 가 최대인 노드 가 지워질 확률이라고 하자. 이렇게 되었을 때, 어떠한 노드 $w$ 가 $u$ 를 지우는 데 기여하려면, $N(u) \cup N(w)$ 에 속하는 정점 중 $w$ 가 최대가 되어야 한다. 고로 $u$ 가 지워질 확률은
$Prob((u, v), u) = \sum_{w \in N(u)} \frac{1}{deg(u) + deg(w)}$
보다 크다. 모든 사건이 서로소이니 합산해도 되고, $|N(u) \cup N(v)| \leq deg(u) + deg(v)$ 이며, $u = v$ 인 경우를 무시했기 때문이다. 비슷한 식으로 $v$가 지워질 확률도 계산할 수 있고, 간선이 지워질 확률은 $\max(Prob(u, v), u), Prob(u, v), v) \geq \frac{Prob((u, v), u) + Prob((u, v), v)}{2}$ 이 된다. 이제 이것의 합을 써 보면:
$\frac{1}{2}\sum_{(u, v) \in E}\sum_{w \in {u, v}} \sum_{x \in N(w)} \frac{1}{deg(x) + deg(w)}$
$=\frac{1}{2}\sum_{w \in V} \sum_{x \in N(w)} \frac{deg(w)}{deg(x) + deg(w)}$
$=\frac{1}{2}(\sum_{(u, v) \in E} \frac{deg(u)}{deg(u) + deg(v)} + \sum_{(v, u) \in E} \frac{deg(u)}{deg(u) + deg(v)})$
$=\frac{|E|}{2}$ $\blacksquare$
Proof of Theorem 12. Luby's Algorithm의 반환값은 올바른 MIS임을 확인할 수 있다. 고로 라운드의 횟수만 증명하면 된다. Lemma 12.1에 따라, $4 \log n$ 번의 라운드 이후 남은 간선 수의 기댓값은 최대 $\frac{1}{n^2}$ 이고, 고로 Markov's inequality에 따라 최소 $1-\frac{1}{n^2}$ 이상의 확률로 종료함을 알 수 있다. $\blacksquare$
References
'공부 > CS theory' 카테고리의 다른 글
- Total
- Today
- Yesterday